jBPM version 6 comes with quite a few improvements that allow developers build their own systems with BPM and BRM capabilities just to name few:
- jar based deployment units - kjar
- deployment descriptors for kjars
- runtime manager with predefined runtime strategies
- runtime engine with configured components
- KieSession
- TaskService
- AuditService (whenever persistence is used)
While these are certainly bringing lots of improvements in embedability of jBPM into custom application they do come with some challenges in terms of how they can be consumed. Several pieces need to come along to have it properly supported and reliably running:
- favor use of RuntimeManager and RuntimeEngine whenever performing work instead of using cached ksession and task service instance
- Cache only RuntimeManager not RuntimeEngine or runtime engine's components
- Creating runtime manger requires configuration of various components via runtime environment - way more simplified compared to version 5 but still...
- On request basis always get new RuntimeEngine with valid context, work with ksession, task service and then dispose runtime engine
All these (and more) were sometimes forgotten or assumed will be done automatically while they weren't. And even more issues could arise when working with different frameworks - CDI, ejb, spring, etc.
Rise of jBPM services (redesigned in version 6.2)
Those who are familiar with jBPM console (aka kie workbench) code base might already be aware of some services that were present from version 6.0 and through 6.1. Module that encapsulated these services is jbpm-kie-services. This module was purely written with CDI in mind and all services within it were CDI based. There was additional code to ease consumption of them without CDI but that did not work well - mainly because as soon as the code was running in CDI container (JEE6 application servers) CDI got into the way and usually caused issues due to unsatisfied dependencies.
So that (obviously not only that :)) brought us to a highly motivated decision - to revisit the design of these services to allow more developer friendly implementation that can be consumed regardless of what framework one is using.
So with the design we came up with following structure:
- jbpm-services-api - contains only api classes and interfaces
- jbpm-kie-services - rewritten code implementation of services api - pure java, no framework dependencies
- jbpm-services-cdi - CDI wrapper on top of core services implementation
- jbpm-services-ejb-api - extension to services api for ejb needs
- jbpm-services-ejb-impl - EJB wrappers on top of core services implementation
- jbpm-services-ejb-client - EJB remote client implementation - currently only for JBoss
Service modules are grouped with its framework dependencies, so developers are free to choose which one is suitable for them and use only that. No more issues with CDI if I don't want to use CDI :)
Let's now move into the services world and see what we have there and how they can be used. First of all they are grouped by their capabilities:
DeploymentService
As the name suggest, its primary responsibility is to deploy (and undeploy) units. Deployment unit is kjar that brings in business assets (like processes, rules, forms, data model) for execution. Deployment services allow to query it to get hold of available deployment units and even their RuntimeManager instances.
NOTE: there are some restrictions on EJB remote client to do not expose RuntimeManager as it won't make any sense on client side (after it was serialized).
So typical use case for this service is to provide dynamic behavior into your system so multiple kjars can be active at the same time and be executed simultaneously.
// create deployment unit by giving GAV
DeploymentUnit deploymentUnit = new KModuleDeploymentUnit(GROUP_ID, ARTIFACT_ID, VERSION);
// deploy
deploymentService.deploy(deploymentUnit);
// retrieve deployed unit
DeployedUnit deployed = deploymentService.getDeployedUnit(deploymentUnit.getIdentifier());
// get runtime manager
RuntimeManager manager = deployed.getRuntimeManager();
Deployment service interface and its methods can be found here.
While it usually is used with combination of other services (like deployment service) it can be used standalone as well to get details about process definition that do not come from kjar. This can be achieved by using buildProcessDefinition method of definition service.
Definition service interface can be found here.
Runtime data service interface can be found here.
Besides lifecycle operations user task service allows:
Complete example with start process and complete user task done by services:
The most important thing when working with services is that there is no more need to create your own implementations of Process service that simply wraps runtime manager, runtime engine, ksession usage. That is already there. It can be nicely seen in the sample spring application that can be found here. And actually you can try to use that as well on OpenShift Online instance here.
Just logon with:
DefinitionService
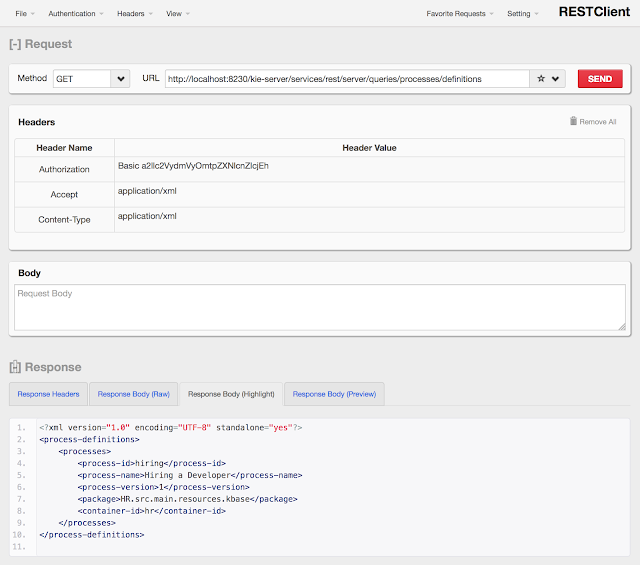
Upon deployment, every process definition is scanned using definition service that parses the process and extracts valuable information out of it. These information can provide valuable input to the system to inform users about what is expected. Definition service provides information about:- process definition - id, name, description
- process variables - name and type
- reusable subprocesses used in the process (if any)
- service tasks (domain specific activities)
- user tasks including assignment information
- task data input and output information
So definition service can be seen as sort of supporting service that provides quite a few information about process definition that are extracted directly from BPMN2.
String processId = "org.jbpm.writedocument";
Collection<UserTaskDefinition> processTasks =
bpmn2Service.getTasksDefinitions(deploymentUnit.getIdentifier(), processId);
Map<String, String> processData =
bpmn2Service.getProcessVariables(deploymentUnit.getIdentifier(), processId);
Map<String, String> taskInputMappings =
bpmn2Service.getTaskInputMappings(deploymentUnit.getIdentifier(), processId, "Write a Document" );
While it usually is used with combination of other services (like deployment service) it can be used standalone as well to get details about process definition that do not come from kjar. This can be achieved by using buildProcessDefinition method of definition service.
Definition service interface can be found here.
ProcessService
Process service is the one that usually is of the most interest. Once the deployment and definition service was already used to feed the system with something that can be executed. Process service provides access to execution environment that allows:- start new process instance
- work with existing one - signal, get details of it, get variables, etc
- work with work items
At the same time process service is a command executor so it allows to execute commands (essentially on ksession) to extend its capabilities.
Important to note is that process service is focused on runtime operations so use it whenever there is a need to alter (signal, change variables, etc) process instance and not for read operations like show available process instances by looping though given list and invoking getProcessInstance method. For that there is dedicated runtime data service that is described below.
An example on how to deploy and run process can be done as follows:
KModuleDeploymentUnit deploymentUnit = new KModuleDeploymentUnit(GROUP_ID, ARTIFACT_ID, VERSION);
deploymentService.deploy(deploymentUnit);
long processInstanceId = processService.startProcess(deploymentUnit.getIdentifier(), "customtask");
ProcessInstance pi = processService.getProcessInstance(processInstanceId);
As you can see start process expects deploymentId as first argument. This is extremely powerful to enable service to easily work with various deployments, even with same processes but coming from different versions - kjar versions.
Process service interface can be found here.
Process service interface can be found here.
RuntimeDataService
Runtime data service as name suggests, deals with all that refers to runtime information:- started process instances
- executed node instances
- available user tasks
- and more
Use this service as main source of information whenever building list based UI - to show process definitions, process instances, tasks for given user, etc. This service was designed to be as efficient as possible and still provide all required information.
Some examples:
1. get all process definitions
Collection definitions = runtimeDataService.getProcesses(new QueryContext());
2. get active process instances
1. get all process definitions
Collection
2. get active process instances
Collection3. get active nodes for given process instanceinstances = runtimeDataService.getProcessInstances(new QueryContext());
Collection4. get tasks assigned to johninstances = runtimeDataService.getProcessInstanceHistoryActive(processInstanceId, new QueryContext());
ListtaskSummaries = runtimeDataService.getTasksAssignedAsPotentialOwner("john", new QueryFilter(0, 10));
There are two important arguments that the runtime data service operations supports:
- QueryContext
- QueryFilter - extension of QueryContext
These provide capabilities for efficient management result set like pagination, sorting and ordering (QueryContext). Moreover additional filtering can be applied to task queries to provide more advanced capabilities when searching for user tasks.
Runtime data service interface can be found here.
UserTaskService
User task service covers complete life cycle of individual task so it can be managed from start to end. It explicitly eliminates queries from it to provide scoped execution and moves all query operations into runtime data service.Besides lifecycle operations user task service allows:
- modification of selected properties
- access to task variables
- access to task attachments
- access to task comments
Complete example with start process and complete user task done by services:
long processInstanceId =
processService.startProcess(deployUnit.getIdentifier(), "org.jbpm.writedocument");
List<Long> taskIds =
runtimeDataService.getTasksByProcessInstanceId(processInstanceId);
Long taskId = taskIds.get(0);
userTaskService.start(taskId, "john");
UserTaskInstanceDesc task = runtimeDataService.getTaskById(taskId);
Map<String, Object> results = new HashMap<String, Object>();
results.put("Result", "some document data");
userTaskService.complete(taskId, "john", results);
That concludes quick run through services that jBPM 6.2 will provide. Although there is one important information left to be mentioned. Article name says it's cross framework services ... so let's see various in action:
- CDI - services with CDI wrappers are heavily used (and by that tested) in jbpm console - kie-wb. Entire execution server that comes in jbpm console is utilizing jbpm services over its CDI wrapper.
- Ejb - jBPM provides a sample ejb based execution server (currently without UI) that can be downloaded and deployed to JBoss - it was tested with JBoss but might work on other containers too - it's built with jbpm-services-ejb-impl module
- Spring - a sample application has been developed to illustrate how to use jbpm services in spring based application
The most important thing when working with services is that there is no more need to create your own implementations of Process service that simply wraps runtime manager, runtime engine, ksession usage. That is already there. It can be nicely seen in the sample spring application that can be found here. And actually you can try to use that as well on OpenShift Online instance here.
 |
| Go to application on Openshift Online |
- john/john1
- mary/mary1
If there is no deployments available deploy one by specifying following string:
org.jbpm:HR:1.0
this is the only jar available on that instance.
And you'll be able to see it running. If you would like to play around with it on you own, just clone the github repo build it and deploy it. It runs out of the box on JBoss EAP 6. For tomcat and wildfly deployments see readme file in github.
That concludes this article and as usual comments and ideas for improvements are more than welcome.
As a side note, all these various framework applications built on top of jBPM services can simply work together without additional configuration just by configuring to be backed by the same data base. That means:
- deployments performed on any of the application will be available to all applications automatically
- all process instances and tasks can be seen and worked on via every application
that provides us with truly cross framework integration with guarantee that they all work in the same way - consistency is the most important when dealing with BPM :)