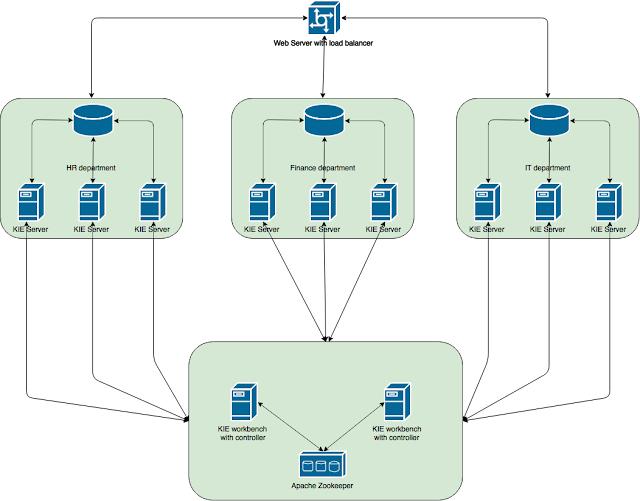
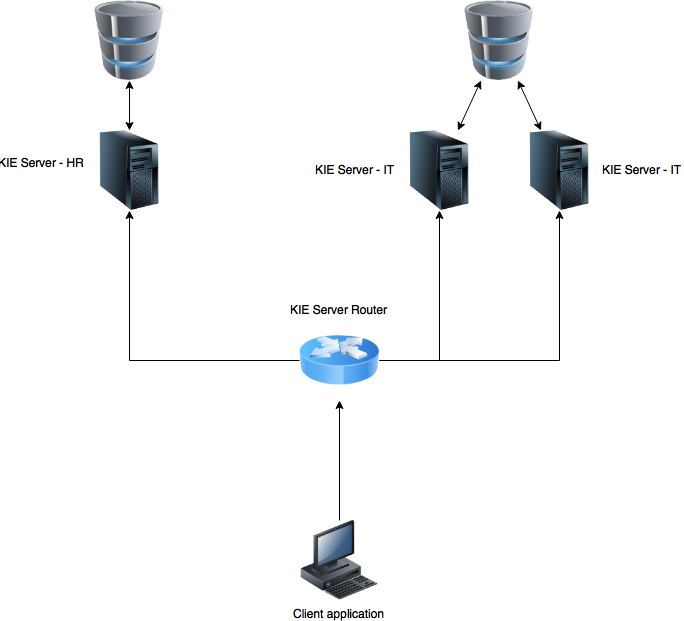
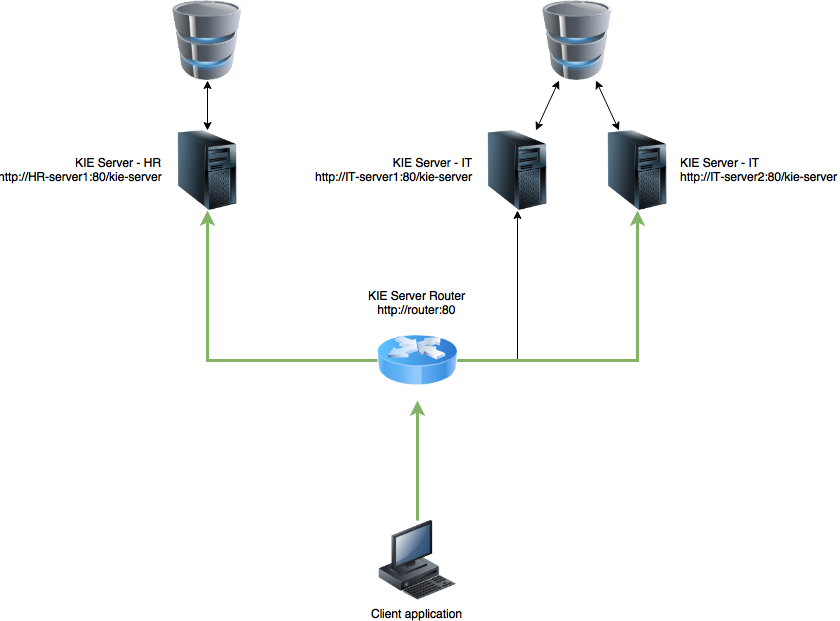
Last but not least part of KIE Server extensions is about extending KIE Server Client with additional capabilities.
META-INF/services/org.kie.server.client.helper.KieServicesClientBuilder
Complete code of this client extension can be found here.
And that's the last extension method to provide more features in KIE Server then given out of the box.
Thanks for reading the entire series of KIE Server extensions and any and all feedback welcome :)
Use case
On top of what was built in second article (adding Mina transport to KIE Server), we need to add KIE Server Client extension that allow to use Mina transport with unified KIE Server Client API.
Before you start create empty maven project (packaging jar) with following dependencies:
<properties>
<version.org.kie>6.4.0-SNAPSHOT</version.org.kie>
</properties>
<dependencies>
<dependency>
<groupId>org.kie.server</groupId>
<artifactId>kie-server-api</artifactId>
<version>${version.org.kie}</version>
</dependency>
<dependency>
<groupId>org.kie.server</groupId>
<artifactId>kie-server-client</artifactId>
<version>${version.org.kie}</version>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<version>${version.org.kie}</version>
</dependency>
</dependencies>
Design ServicesClient API interface
First thing we need to do is to decide what API we should have to be exposed to the callers of our Client API. Since the Mina extension is an extension on top of Drools one so let's provide same capabilities as RulesServicesClient:
public interface RulesMinaServicesClient extends RuleServicesClient {
}
As you can notice it simply extends the default RulesServiceClient interface and thus provide same capabilities.
Why we need to have additional interface for it? It's because we are going to register client implementations based on their interface and there can be only one implementation for given interface.
Implement RulesMinaServicesClient
Next step is to actually implement the client and here we are going to prepare a socket based communication for simplicity sake. We could use Apache Mina client API though this would introduce additional dependency which we don't need for sample implementation.
Note that this client implementation is very simple and in many cases can be improved, but the point here is to show how it can be implemented rather than provide bullet proof code.
So few aspects to remember when reviewing the implementation:
- it relies on default configuration from KIE Server client and thus uses serverUrl as place where to provide host and port of Mina server
- hardcodes JSON as marshaling format
- decision if the response is success or failure is based on checking if the received message is a JSON object (start with {) - very simple though works for simple cases
- uses direct socket communication with blocking api while waiting for first line of the response and then reads up all lines that are available
- does not use "stream mode" meaning it disconnects from the server after invoking command
Here is the implementation
public class RulesMinaServicesClientImpl implements RulesMinaServicesClient {
private String host;
private Integer port;
private Marshaller marshaller;
public RulesMinaServicesClientImpl(KieServicesConfiguration configuration, ClassLoader classloader) {
String[] serverDetails = configuration.getServerUrl().split(":");
this.host = serverDetails[0];
this.port = Integer.parseInt(serverDetails[1]);
this.marshaller = MarshallerFactory.getMarshaller(configuration.getExtraJaxbClasses(), MarshallingFormat.JSON, classloader);
}
public ServiceResponse<String> executeCommands(String id, String payload) {
try {
String response = sendReceive(id, payload);
if (response.startsWith("{")) {
return new ServiceResponse<String>(ResponseType.SUCCESS, null, response);
} else {
return new ServiceResponse<String>(ResponseType.FAILURE, response);
}
} catch (Exception e) {
throw new KieServicesException("Unable to send request to KIE Server", e);
}
}
public ServiceResponse<String> executeCommands(String id, Command<?> cmd) {
try {
String response = sendReceive(id, marshaller.marshall(cmd));
if (response.startsWith("{")) {
return new ServiceResponse<String>(ResponseType.SUCCESS, null, response);
} else {
return new ServiceResponse<String>(ResponseType.FAILURE, response);
}
} catch (Exception e) {
throw new KieServicesException("Unable to send request to KIE Server", e);
}
}
protected String sendReceive(String containerId, String content) throws Exception {
// content - flatten the content to be single line
content = content.replaceAll("\\n", "");
Socket minaSocket = null;
PrintWriter out = null;
BufferedReader in = null;
StringBuffer data = new StringBuffer();
try {
minaSocket = new Socket(host, port);
out = new PrintWriter(minaSocket.getOutputStream(), true);
in = new BufferedReader(new InputStreamReader(minaSocket.getInputStream()));
// prepare and send data
out.println(containerId + "|" + content);
// wait for the first line
data.append(in.readLine());
// and then continue as long as it's available
while (in.ready()) {
data.append(in.readLine());
}
return data.toString();
} finally {
out.close();
in.close();
minaSocket.close();
}
}
}
Once we have the client interface and client implementation we need to make it available for KIE Service client to find it.
Implement KieServicesClientBuilder
org.kie.server.client.helper.KieServicesClientBuilder is the glue interface that allows to provide additional client apis to generic KIE Server Client infrastructure. This interface have two methods:- getImplementedCapability - which must much the server capability (extension) is going to use
- build - which is responsible for providing map of client implementations where key is the interface and value fully initialized implementation
Here is a simple implementation of the client builder for this use case
public class MinaClientBuilderImpl implements KieServicesClientBuilder {
public String getImplementedCapability() {
return "BRM-Mina";
}
public Map<Class<?>, Object> build(KieServicesConfiguration configuration, ClassLoader classLoader) {
Map<Class<?>, Object> services = new HashMap<Class<?>, Object>();
services.put(RulesMinaServicesClient.class, new RulesMinaServicesClientImpl(configuration, classLoader));
return services;
}
}
Make it discoverable
Same story as for other extensions ... once we have all that needs to be implemented, it's time to make it discoverable so KIE Server Client can find and register this extension on runtime. Since KIE Server Client is based on Java SE ServiceLoader mechanism we need to add one file into our extension jar file:
And the content of this file is a single line that represents fully qualified class name of our custom implementation of KieServicesClientBuilder.
How to use it
The usage scenario does not much differ from regular KIE Server Client use case:
- create client configuration
- create client instance
- get service client by type
- invoke client methods
Here is implementation that create KIE Server Client for RulesMinaServiceClient
protected RulesMinaServicesClient buildClient() {
KieServicesConfiguration configuration = KieServicesFactory.newRestConfiguration("localhost:9123", null, null);
List<String> capabilities = new ArrayList<String>();
// we need to add explicitly capabilities as the mina client does not respond to get server info requests.
capabilities.add("BRM-Mina");
configuration.setCapabilities(capabilities);
configuration.setMarshallingFormat(MarshallingFormat.JSON);
configuration.addJaxbClasses(extraClasses);
KieServicesClient kieServicesClient = KieServicesFactory.newKieServicesClient(configuration);
RulesMinaServicesClient rulesClient = kieServicesClient.getServicesClient(RulesMinaServicesClient.class);
return rulesClient;
}
And here is how it is used to invoke operations on KIE Server via Mina transport
RulesMinaServicesClient rulesClient = buildClient();
List<Command<?>> commands = new ArrayList<Command<?>>();
BatchExecutionCommand executionCommand = commandsFactory.newBatchExecution(commands, "defaultKieSession");
Person person = new Person();
person.setName("mary");
commands.add(commandsFactory.newInsert(person, "person"));
commands.add(commandsFactory.newFireAllRules("fired"));
ServiceResponse<String> response = rulesClient.executeCommands(containerId, executionCommand);
Assert.assertNotNull(response);
Assert.assertEquals(ResponseType.SUCCESS, response.getType());
String data = response.getResult();
Marshaller marshaller = MarshallerFactory.getMarshaller(extraClasses, MarshallingFormat.JSON, this.getClass().getClassLoader());
ExecutionResultImpl results = marshaller.unmarshall(data, ExecutionResultImpl.class);
Assert.assertNotNull(results);
Object personResult = results.getValue("person");
Assert.assertTrue(personResult instanceof Person);
Assert.assertEquals("mary", ((Person) personResult).getName());
Assert.assertEquals("JBoss Community", ((Person) personResult).getAddress());
Assert.assertEquals(true, ((Person) personResult).isRegistered());
Complete code of this client extension can be found here.
And that's the last extension method to provide more features in KIE Server then given out of the box.
Thanks for reading the entire series of KIE Server extensions and any and all feedback welcome :)